


Objectifs d'apprentissage de ce TD
À la fin de ce TD, tu seras en mesure :
- de calculer des indices spectraux avec une calculatrice raster à l'aide d'une formule ;
- de classifier de manière supervisée une image de télédétection multi-bande à l'aide de l'OTB et d'estimer sa qualité à l'aide d'une matrice de confusion et d'indices qui en sont dérivés. Plus spécifiquement tu seras en mesure de :
- produire une carte d’occupation des sols par classification supervisée :
- comprendre le principe de la classification supervisée ;
- citer les deux étapes d’une classification ;
- entrainer un modèle ;
- appliquer un modèle ;
- choisir une stratégie d’entrainement et de validation de modèle sans biais en séparant le jeux de référence en un jeu d'entrainement/validation ;
- évaluer la qualité d'une carte et :
- produire une matrice de confusion ;
- produire des indices de qualité de la classification ;
- savoir lire une matrice de confusion ;
- citer la définition des indices de qualité ;
- identifier les confusions principales .
- produire une carte d’occupation des sols par classification supervisée :
Les données
Tu peux télécharger les données nécessaires à ce TD 👉 ici. 👈 Attention ce lien expire le 18 octobre
: Des données !
1. Télécharge les données
2. Mets l'archive zip dans un endroit adapté sur ton ordinateur (l'endroit où sont installés tes programmes n'est par exemple pas adapté 😉) ;
3. Extrait (aka "dézippe") l'archive (si tu n'as aucune idée de ce que ça veut dire, demande rapidement à Google).
4. Marque dans l'exercice comme terminé dans Moodle.
Ma première carte
Production de la carte
Allons y let's go, attelons nous sans transition à faire ta première carte. Lis quand même ces quelques conseils de Jean-Michel Télédétection avec de commencer, ils pourront te faire gagner du temps et économiser ta patience.
Tips n°1 : Prend l'habitude de ne mettre ni accents, ni espaces dans tes chemins de fichier (et pas seulement les noms). Si tu ne fais pas ça, ça peut planter. C'est d'autant plus vicieux que cette précaution n'est pas utile pour tous les paramètres, sauf que tu ne peux pas le savoir à l'avance ...
Tips n°2 : Pour les paramètres de sorties, prend l'habitude de mettre le chemin complet des fichiers en incluant l'extension des fichiers (.tif, .txt, .csv etc.), ça sera plus facile pour retrouver tes fichiers 😉
Tips n°3 : Si tu vois du rouge dans le journal de l'application, ça veut probablement dire qu'il y a eu un problème avec le traitement qui vient d'être lancé. Mais pas toujours ! Vérifie à tout hasard si le(s) fichier(s) de résultat ont bien été produits ou pas.
Tips n°4 : l'interface de Mapla n'est pas idéale pour naviguer et indiquer le chemin des fichiers en entrée ou en sortie. Pour aller plus vite, tu peux copier un fichier dans ton explorateur classique et le coller dans la barre de saisie. Cela copiera en fait son chemin d'accès !
Tips n°5 : pense à agrandir tes fenêtres de traitements ou de faire déroulé les paramètres si tu ne les vois pas tous 😉
: Ma première classification
Tu vas réaliser une première classification, pas à pas. Les fonctionnalités d'OTB que tu vas utiliser ne sont pas bien implémentées dans QGIS. tu vas donc utiliser le lanceur d'application Mapla (c'est ici pour celleux qui ont oublié comment faire).
1. Ouvre le lanceur d'application Mapla.
2. Entraine ton premier modèle de classification :
- Ouvre l'application TrainVectorClassifier ;
- Remplis les champs suivants :
Input Vector Data: le fichier d'échantillonssamples_ready.shp;Output model:/mon/repertoire/de/resultat/mon_premier_model.txt;Field names for training features: sélectionne les champs suivants :b0;b1;b2;b3
Field conaining the class integer label for supervision:numLabel1;Classifier to use for the training:Decision Tree classifier;
- Laisse les autres paramètres avec leurs valeurs par défaut.
3. Classe les pixels d'une image :
- Ouvre l'application ImageClassifier ;
- Remplis les champs suivants :
Input Image: l'imagefabas_octobre_2013.tif;Model file: :/mon/repertoire/de/resultat/mon_premier_model.txt;Output Image:/mon/repertoire/de/resultat/ma_premiere_classif.tif;
- Laisse les autres paramètres avec leurs valeurs par défaut.
4. Ouvre ta classification dans QGIS. Regarde ta carte, elle est belle non ?
5 Marque dans l'exercice comme terminé dans Moodle.
Mais qu'a-t-on fait au juste ?
Bravo, munis d'un jeu d'échantillons tout prêt et d'une image toute prête, tu sais faire une carte 💪. Comment ? Tu ne sais pas encore mais bientôt.
: Tu te poses et tu essaies de comprendre ce que tu as fait.
Question n°1 : Mais c'est quoi cette carte ?
-
que contient-elle ?
- quelle est le type des données de l'image ?
- les données sont de type discret ou continu ?
-
à quoi correspondent ses valeurs ?
Question n°2 : À quoi correspond la première étape ? C'est quoi l'entrainement d'un modèle ?
- D'après les paramètres indiqués dans l'exercice précédent, quels sont les échantillons de références utilisés ? Quelle est le type de ses géométries ?
- Quelle est la nomenclature utilisée ?
- D'après les paramètres indiqués dans l'exercice précédent, quelles sont les primitives utilisées ? Où peut-on trouver leurs valeurs pour chaque échantillon ?
Question n°3 : Que vaut cette carte ?
- Visuellement ça te semble correct ?
- Comment pourrais-tu faire pour évaluer sa qualité ? Écris le avec tes propres mots et en rediscute après.
Marque dans l'exercice comme terminé dans Moodle.
On fait le point tous ensemble dans quelques minutes .
Validation de la carte
Dans cette partie tu vas produire une estimation de la qualité de ta carte à partir d'une matrice de confusion.
Quelques rappels si tu ne te souviens pas de ces indices :
RAPPEL : qualité d'une carte
Matrice de confusion

Accord Globale
C'est le pourcentage de pixels bien classés, ce qui correspond à la somme de la diagonale de la matrice de confusion:
Au dessus de ce conseil, il y a une formule qui est censée s'afficher comme ça :
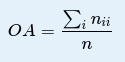
si au contraire tu vois quelque chose comme çà :
OA = \frac{\sum_i n_{ii}}{n}\\ Sois sérieux.se et ferme ton navigateur Edge et ouvre cette page web dans Mozilla voire Chrome. Ça devrait mieux s'afficher. Si toujours pas, parles-en à ton prof, il n'a qu'à mieux configurer sa page web !
Rappel (aka précision réalisateur)
C'est le pourcentage des pixels de référence d'une classe effectivement classés dans la classe par le modèle. Cela correspond aux pixels bien classées de la classe divisé (dans la digonale) par la somme des pixels de la ligne correspondante :
Cette métrique permet de répondre à la question : "Le modèle permet-il de bien détecter la classe ?" ou "Des pixels de la classe ont-ils été oubliés par le modèle ?". Un score faible vous indiquera que non (ou oui pour la deuxième question) et que la classe i est probablement sous détectée dans la carte finale (d'où le lien avec l'erreur d'omission).
Précision (aka précision utilisateur)
C'est le pourcentage de pixels classés comme une classe par le modèle qui correspondent effectivement à cette classe d'après la référence. Cela correspond aux pixels bien classées de la classe (dans la diagonale) divisé par la somme des pixels de la colonne correspondante :
Cette métrique permet de répondre à la question : "Les pixels de la classe dans ma carte finale appartiennent-ils vraiment à la classe ?". Un score faible vous indiquera que non et que la classe est probablement sur détectée dans la carte finale (d'où le lien avec l'erreur de commission).
Lien entre Rappel et Précision
Une classe peut avoir un très bon rappel et une très mauvaise précision : dans ce cas là, le modèle détecte très bien la classe (= bon rappel) mais probablement parce qu'il a tendance à classer beaucoup trop de pixels dans cette classe (mauvaise précision et beaucoup d'erreurs de commission).
Inversement, une classe peut avoir un très mauvais rappel et une très bonne précision : dans ce cas là, le modèle détecte mal la classe (= mauvais rappel et beaucoup d'erreurs d'omission) mais par contre, on est sûr que les pixels classés sont bien de la classe (bonne précision).
Enfin, on peut avoir une mauvaise précision et un mauvais rappel pour une classe : certains pixels ne sont pas détectés comme tels par le modèle et tous les pixels détectés comme étant de la classe n'appartiennent pas à cette classe.
Il est donc important de considérer ces deux métriques pour estimer la qualité d'une classe.
F1-score (ou F-measure ou F-score)
Le F score peut s'interpréter comme étant la moyenne harmonique de la précision et du rappel. La meilleure valeur possible est 1 tandis que la moins bonne possible est 0. Cette métrique est un résumé intéressant de la qualité d'une classe car elle prend en compte les erreurs d'omission et de commision, bien qu'il ne soit pas possible d'analyser en détails ces types d'erreurs.
: Estimation de la qualité d'une carte.
Attention, cliqueur fou, aux paramètres que tu choisis ! Pour rappel, on veut bien une matrice de confusion établie d'après des échantillons de références. Or, quel est le format des échantillons dont tu disposes ?
1. Produis la matrice de confusion et enregistre là à l'aide de l'application ComputeConfusionMatrix. Le format de sortie attendu est le format csv (.csv).
INFO : Si tu ne sais pas ce qu'est un fichier CSV.
C'est un fichier texte. Pour t'en convaincre ouvre le avec n'importe quel éditeur de texte (notepad++, word, gedit etc.).
C'est plus précisément un fichier texte qui contient des données sous forme de "tableau". Les lignes sont représentées par des retours à la ligne tandis que les colonnes sont représentées par un caractère spécifique. La plupart du temps c'est une virgule , (d'où le nom csv : comma separated value), mais ce peut être n'importe quel symbole : des tabulations, des espaces, des antislash \ ou, plus courramment en france, un point-virgule ;.
Comme c'est un tableau, il est possible de l'ouvrir avec un tableur. Il faut alors spécifier au tableur quel est le caractère qui sert de séparateur de colonne.
2. Ouvre la matrice de confusion dans un tableur (Excel/ Tableur libre office) et produis les indices de qualité suivants (à l'aide du rappel au besoin):
- l'accord global ;
- la précision de chaque classe (ou précision utilisateur ou erreur de commision) ;
- le rappel de chaque classe (ou précision réalisateur ou erreur d'omission).
Quelques précisions :
- oui, il faut entrer les formules à la main dans les cellules ;
- quand tu ouvres la matrice, elle n'est pas tout a fait prête à l'emploi : le label des classes est sous forme numérique et est stocké dans une entête (les deux premières lignes du fichier);
- voici un exemple de formattage d'une matrice de confusion :

3. Reporte tes résultats sur cette feuille de calcul collaborative :
Ne porte pas attention aux colonnes Train/Valid et Option.
4. Interprète tes résultats et propose une analyse de la qualité de la carte produite. Il y a beaucoup d'information, je te propose de toujours aller du plus général au plus détaillé :
- la qualité globale de la classification est-elle bonne ?
- quelles classes sont mal classées ?
- quelles sont les plus grosses confusions ?
5 Marque dans l'exercice comme terminé dans Moodle.
Tu as calculé les indices à la main pour bien comprendre ce qu'il se passe MAIS
à l'avenir tu peux directement trouver les indices de qualité dans les logs de l'application OTB ComputeConfusionMatrix. Tu peux ainsi vérifier tes précédents calculs.
Tu peux remarquer à ce stade là qu'il est possible, en théorie, d'analyser la qualité d'une image de classification sans même l'ouvrir. C'est par contre une très mauvaise pratique. Il est toujours recommandé de compléter l'analyse statistique de la qualité par une analyse visuelle.
: Analyse visuelle d'une carte
- 1. Améliore le rendu visuel de l'image classée
- 1.1. soit manuellement en changeant le mode de représentation de l'image [Palette /Uniques]
- 1.2 soit automatiquement en utilisant la palette qui t'est fournie
palette_niv1.qml
- 2. Repère dans l'image classée les erreurs de commision et d'omission que tu as relevées dans la matrice de confusion.
- 3. Repères-tu dans l'image classée des erreurs que tu n'aurais pas relevées dans la matrice de confusion ?
4 Marque dans l'exercice comme terminé dans Moodle.
Un peu de théorie
Classification supervisée
Tu viens donc d'effectuer une classification d'images de télédétection de manière supervisée. Il s'agissait d'attribuer un label aux pixels d'une image en fonction de leur comportement radiométrique (bien que ce fut transparent pour toi).
Avec les algorithmes de classification supervisée, les règles de décision permettant d'attribuer un label à une classe sont calculées automatiquement à partir d'échantillons de référence. Pour entraîner un algorithme de classification supervisée, il faut donc disposer d'échantillons d'apprentissage, c'est à dire des pixels dont on connait a priori la nature, des pixels déjà labelisés.
De manière analogue, des échantillons de référence sont également nécessaires pour valider la qualité d'une carte ou du modèle dont elle est issue, on les appelera aussi échantillons de validation.
SOYONS PRÉCIS·ES : label ou étiquette ?
Le terme "label" est employé dans tout ce TD, mais c'est un anglicisme. Les ergoteurs puristes utiliseront plutôt le terme "étiquette". De même, au lieu de labéliser, on pourra utiliser le terme ""étiquetter" qui est plus français 🐓. Ne sois donc pas étonné·e si tu croises ces deux termes plus tard. Personnellement, j'utilise "label" car je le rencontre plus souvent, tout simplement.
Tu trouveras ci dessous une figure synthétisant les étapes à réaliser lors d'une classification. La première partie est un schéma théorique tandis que les deux suivantes correspondent à l'implémentation de la première avec l'OTB, selon deux options différentes.
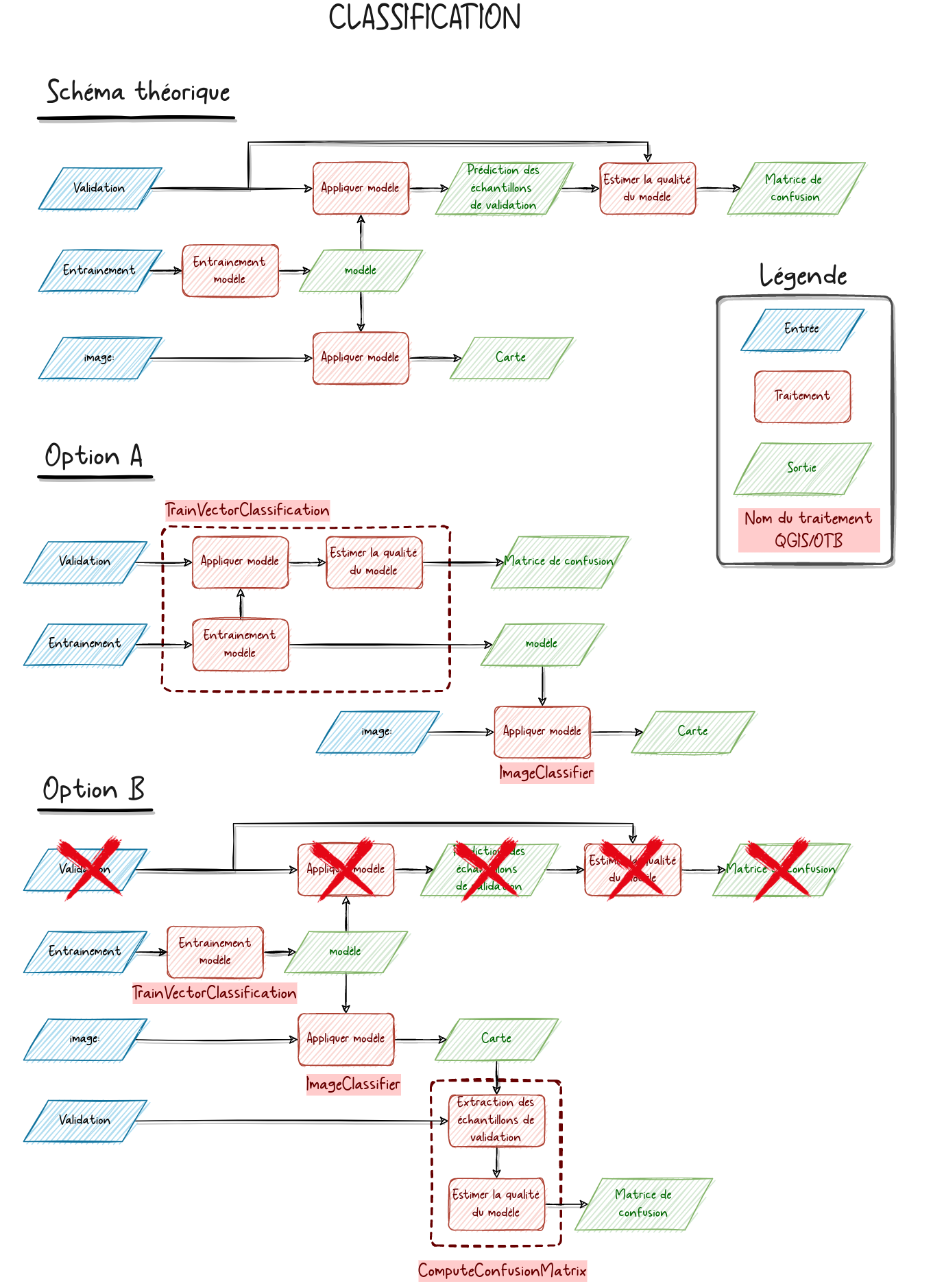
: Comprends-tu ce schéma ?
Question n°1 : Selon toi, quelle option as tu réalisée plus tôt ?
Question n°2 : Les deux options sont-elles équivalentes ? Dans quels cas l'une serait mieux que l'autre ?
Question n°3 : Quel était le fichier utilisé pour :
- l'image ?
- l'entrainement ?
- la validation ?
Question n°4 : Et ça ne t'interpelle pas ?
5 Marque dans l'exercice comme terminé dans Moodle.
Les échantillons de référence
Réflechissons maitnenant aux échantillons.
Le premier point qui a du t'interpeller plus tôt, c'est le fait que le fichier d'échantillons utilisé pour l'entrainement et pour la validation était le même. Il faut qu'ils soient différents si on ne veut pas que l'estimation de la qualité de la classification soit trop biaisée. Il va donc falloir séparer le jeu initial en deux jeux distincts.
Le deuxième point qui a pu t'interpeller est la position des échantillons. Avais-tu remarqué qu'ils étaient centrés sur les pixels de l'image fabas_decembre_2013.tif ? Les échantillons ont en fait été préparés pour que tu pusses les utiliser directement et faire ta carte. Ce dont avait besoin l'outil TrainVectorClassification était une table contenant un label de classe et des valeurs de primitives associées pour chaque échantillon (voir Figure ci dessous). L'obtention de cette table a nécessité quelques traitements que nous allons aborder maintenant.
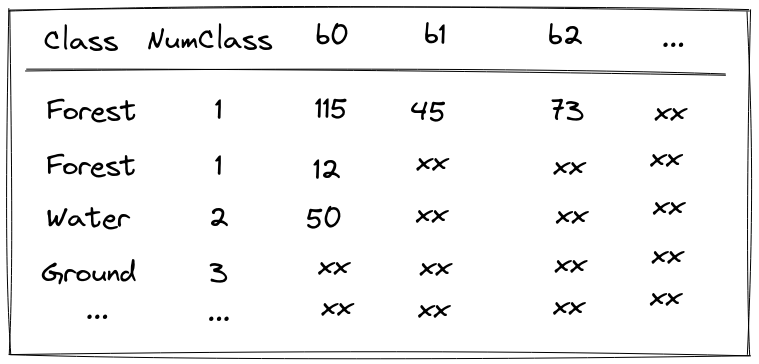
b0, b1 etc.) et des labels, sous forme de chaîne de caractère (ici Class) ou sous forme d'entier (ici NumClass).Premièrement, les données de références peuvent être contenu dans des fichiers vecteur de polygones plutôt que de points. C'est particulièrement vrai lorsque les références proviennent de données exogènes comme la BD TOPO, le RPG ou encore CLC. Il est donc nécessaire de convertir des échantillons-polygones en échantillons-points (étape 1 dans la figure ci-dessous).
Deuxièmement, il est nécessaire d'extraire pour chaque échantillon-point, les valeurs spectrales à utiliser pour la classification, en fonction de leur position par rapport à l'image à utiliser (étape 2 dans la figure ci-dessous).
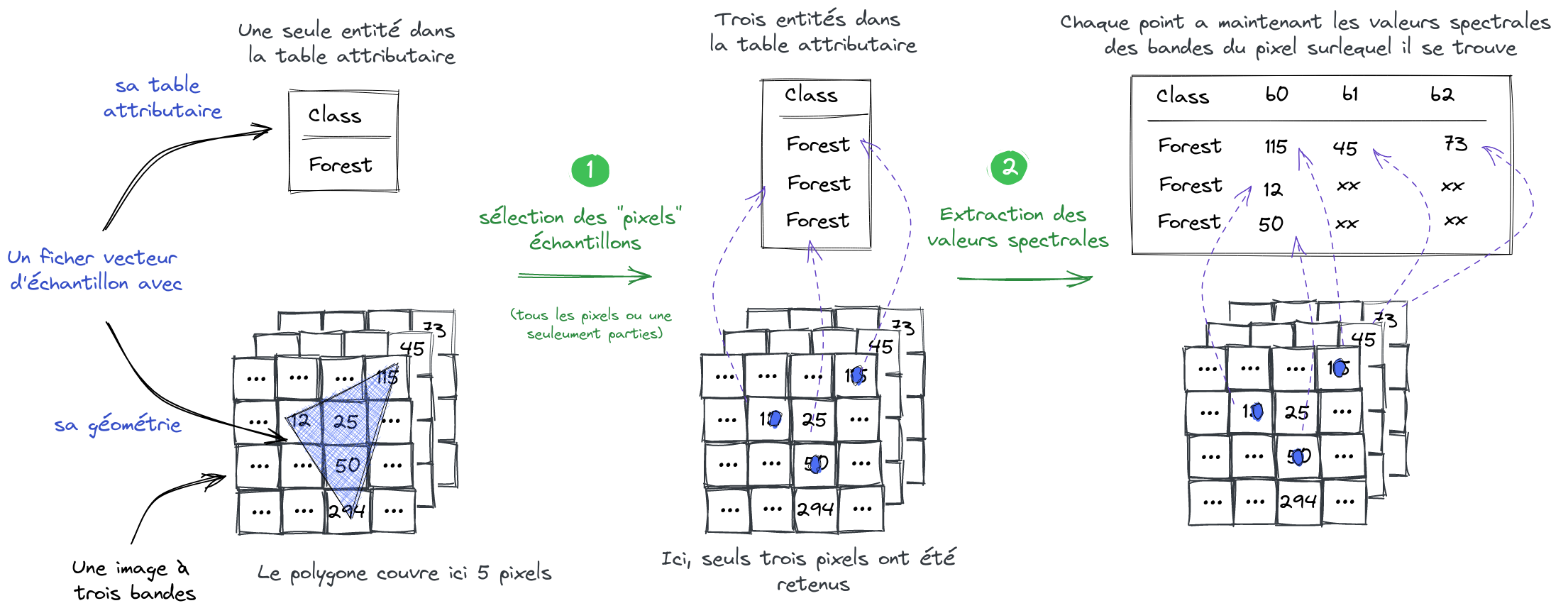
INFO : Sélection des échantillons, équilibre des classes.
En plus de la conversion, il est possible de réaliser une étape de sélection des points. Il est ainsi possible de :
- sélectionner un nombre équivalement d'échantillons pour chaque classe :
- basé sur la classe contenant le moins d'échantillons ;
- selon un nombre constant à déterminer ;
- sélectionner seuleument une proportion des échantillons, en respectant de fait les porportions initiales de chaque classe.
- etc.
Dans ce TD, nous n'aborderons pas cet aspect et nous prendrons tous les échantillons-points constitutifs des polygones d'origine. Ce qui est illustré dans la figure ci dessus l'est seulement à titre d'exemple.
Pour plus d'infos sur les différentes manières de sélectionner les échantillons, tu peux te référer à la documentation de l'OTB.
Tu as donc maintenant compris qu'avant de pouvoir utiliser des échantillons pour entrainer un modèle de classification, il faut d'abord les préparer et séparer le jeu initial en un jeu d'apprentissage et de validation. Voici ci-dessous l'enchainement des outils à utiliser pour obtenir un fichier d'échantillons prêt pour l'entrainement d'un modèle.
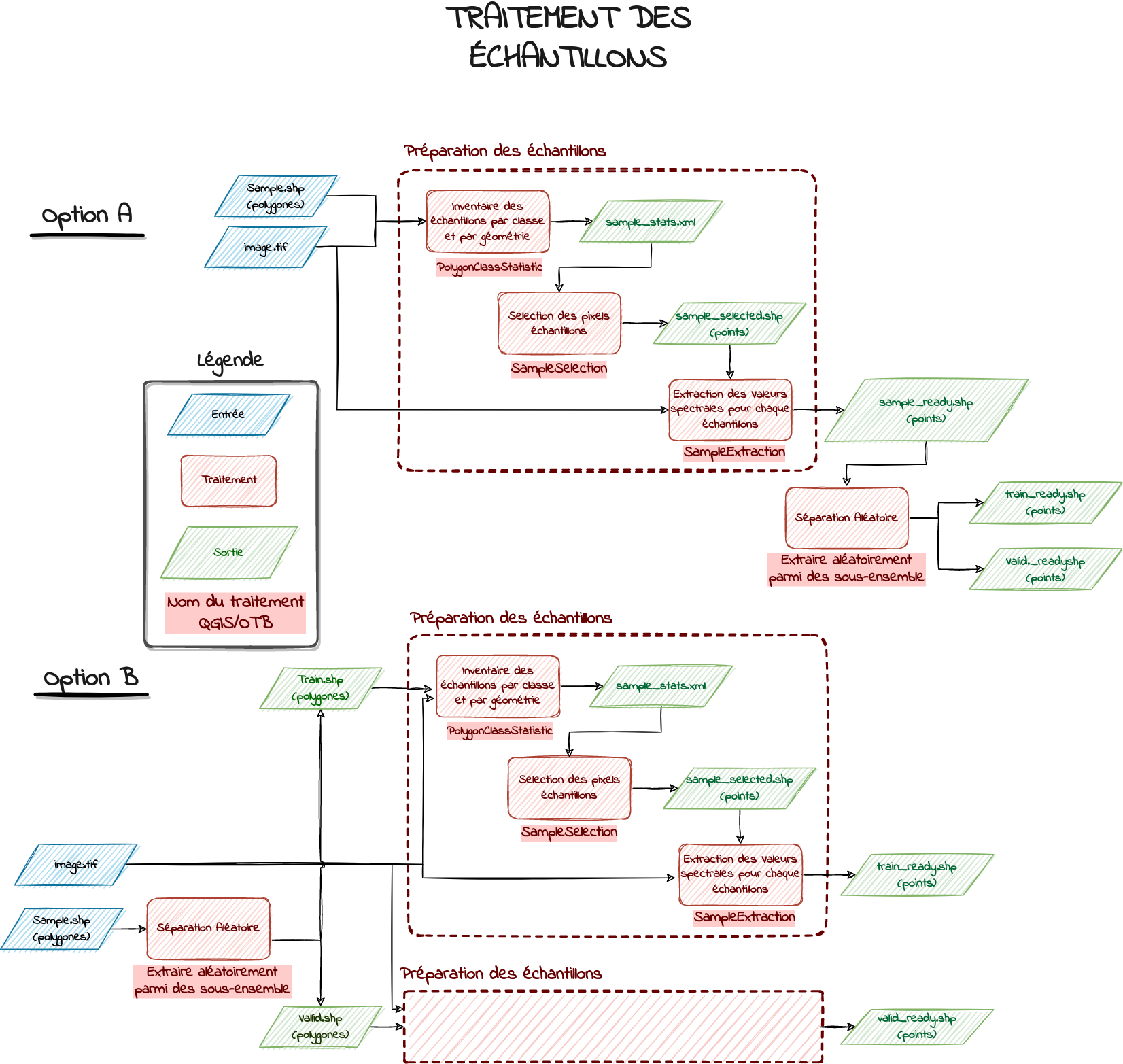
: Comprends-tu ce schéma ?
Question n°1 :
- Dans le schéma, un seul traitement n'a pas été directement mentionné, lequel est-ce ?
- Selon toi, pourquoi est-il nécessaire (des élements de réponses sont présents dans le dernier encart d'information) ?
Question n°2 : En quoi les deux options ne sont pas équivalentes ?
3 Marque dans l'exercice comme terminé dans Moodle.
Pour ce TD, les échantillons de référence sont fournis sous forme de polygones ou de points, dépendemment du niveau de nomenclature considéré.
Un premier fichier de polygone sample.shp correspond à deux premiers niveaux de nomenclature :
| Label1 | NumLabel1 | Label2 | NumLabel2 |
|---|---|---|---|
| Eau | 1 | Eau | 10 |
| Bâti | 2 | Bâti | 20 |
| Sol Nu | 3 | Sol Nu | 30 |
| Culture | 4 | Culture | 40 |
| Végétation ligneuse | 5 | Feuillus | 51 |
| Résineux | 52 | ||
Un deuxième fichier de point tree_species.shp correspond à un troisième niveau de nomenclature :
| Label3 | numLabel3 |
|---|---|
| Eau | 100 |
| Bati | 200 |
| Sol nu | 300 |
| Culture | 400 |
| AUTRES FEUILLUS | 510 |
| CHENE | 511 |
| ROBINIER | 512 |
| AUTRES RESINEUX | 520 |
| DOUGLAS | 521 |
| PIN LARICIO | 523 |
| PIN MARITIME | 524 |
| PIN WEYMOUTH | 525 |
Deuxième carte : validation avec de bons échantillons
Production des jeux d'échantillons
HOW TO : Séparation des échantillons
Attention, sur le schéma présentant la chaîne de traitement des échantillons, il est fait référence au traitement Extraire aléatoirement parmi des sous-ensembles. Si ce traitement permet bien de créer un fichier avec une sous partie de manière aléatoire, il sera compliqué de produire dans un deuxième temps le jeu d'échantillons complémentaire. Dit autrement, si vous appliquez deux fois le traitement, vous aurez bien deux sous-jeux produits de manière aléatoire, mais il est très probable qu'il y ait des échantillons communs entre les deux fichiers, ce qu'on veut justement éviter !
Pour avoir deux jeux complétement disjoints, tu vas plutôt procéder en deux étapes :
- utilise plutôt l'outil Sélection aléatoire parmi des sous-ensembles. Cet outil ne produit pas de fichier mais permet une sélection (tu peux t'en assurer en regardant la table attributaire);
- dans un second temps, exporte uniquement la sélection en faisant Clique droit sur la couche d'échantillons ► exporter ► sauvegarder les entités sélectionnées sous.
Ensuite pour produire le jeux d'échantillons complémentaire, il faut :
- aller dans la table attributaire de la couche d'échantillons complète ;
- inverser la sélection (petite icone en haut de la table attributaire
 ) .
) .
: Production de jeux d'échantillons disctincts pour l'entrainement et la validation.
Tu vas maintenant produire ton jeu d'échantillons en suivant la chaine de traitement de la Figure 4. Pour savoir selon quelles proportions tu dois répartir les échantillons en un jeu d'entrainement et de validation, et quelle chaîne de traitement choisir, réfère toi aux colonnes Train/Valid et Option de la feuille de calcul que vous avez déjà remplie pour l'exercice "Estimation de la qualité d'une carte" :
Voici quelques indications à garder en tête pendant la réalisation de la chaîne de traitement. L'objectif est :
- d'extraire les valeurs spectrales de l'image
fabas_octobre_2013.tif; - de garder tous les pixels inclus dans les polygones de référence ;
- d'utiliser les échantillons pour une classification selon le niveau de nomenclature
NumLabel1.
Tips n°1 : N'oublie pas d'utiliser l'application Mapla.
Tips n°2 : Pour une fois, on ne te dis pas exactement quoi remplir pour tous les paramètres. Si tu as des doutes, n'oublie pas que tu peux (dois) te référer à la documentation de l'outil que tu utilises. En revanche, sache qu'avec une doc, tu as les infos nécessaires et suffisantes pour savoir quels paramètres remplir et comment, et ceux que tu peux laisser avec leur valeur par défaut.
Tips n°3 : quand tu as besoin d'appeler le prof, ne te contente surtout pas d'un : "Monsieur, ça marche pas" ... 🙅 ce n'est pas informatif et ça peut l'énerver (si si). Imagine un peu aller sur un forum et poster "Salut, ça ne marche pas, quelqu'un peut m'aider ?". Prépare donc ta question, recontextualise ton problème, explicite ton erreur et comment tu as fait pour l'obtenir 🙏.
Ré-estimation de la qualité
Maintenant que tu disposes d'échantillons de validation et d'entrainement distincts, tu vas pouvoir estimer avec moins de biais la qualité de ta carte.
: Ma deuxième classification.
Tu vas cette fois-ci utiliser la chaîne de traitement "Option A" (de la Figure 1), c'est à dire que tu vas entrainer et valider ton modèle avec la même application TrainVectorClassifier. Tu produiras dans un second temps ta carte.
Tu entraineras ton modèle avec les mêmes paramètres que dans l'exercice Ma première classification.
Reportes tes resultats dans la feuille de calcul collaborative. J'utiliserai les résultats de chacun·e pour faire une comparaison des estimations de la qualité de cet exercice et de celles de l'exercice 2.
Marque dans l'exercice comme terminé dans Moodle.
Post classification
Filtre majoritaire
Il est possible de réaliser des traitements post-classification sur une image déjà classifiée. Il est par exemple possible d'appliquer des filtres sur une image pour supprimer un effet poivre et sel.

Tu peux appliquer un filtre à l'aide de l'application ClassificationMapRegularization
: Appliquer un filtre majoritaire.
1. Applique le filtre sur ta classification avec un filtre 3 x 3 (paramètre Structuring Element Radius = 1)
2. Vérifiez que l'opération a bien fonctionné en visualisant le résultat dans QGIS;
3. Calcule la qualité de cette nouvelle classification.
Reporte tes résultats sur la feuille de calcul collaborative.
4. Teste d'autres tailles de filtre en observant :
- de manière visuelle l'effet du filtre;
- l'impact sur l'estimation de la qualité de la classification.
5 Marque dans l'exercice comme terminé dans Moodle.
Regrouper des classes
Une possibilité pour améliorer ta classification est de regrouper des classes qui ont beaucoup de confusion entre elles a posteriori. Dans notre cas, la classe "Sol nu" (classe 3) et "Bâti" ont beaucoup de confusion (classe 2).
Pour observer le résultats sur la carte, tu peux utiliser la calculatrice raster pour changer la valeur d'une classe vers une autre classe (cf TD précédent).
Pour observer le changement sur la matrice de confusion :
- recalculer la matrice de confusion à partir de la nouvelle classification avec les classes regroupées et à partir d'échantillons avec les labels actualisées (c.a.d. avec un label numérique commun pour les classes
batietsol nu). - soit actualiser directement à la main la matrice de confusion :
- en additionnant les lignes des classes concernées ;
- puis en additionnant les colonnes des classes concernées.
: Regrouper des classes --> évaluation de l'effet sur la qualité du résulat ?
Évalue l'effet du regroupement des classes bati et sol nu :
- visuellement sur la classification avec les classes regroupées ;
- sur l'estimation de la qualité (avec la matrice de confusion donc).
Marque dans l'exercice comme terminé dans Moodle.
Facteurs influençant les résultats
Bilan des étapes précédentes
Finalement, l'ensemble des traitements que tu as faits peut se résumer dans la figure ci-dessous. Dans ce schéma figure l'option A de la classification de l'image et l'option A de la préparation des échantillons, mais les deux options sont aussi valables.
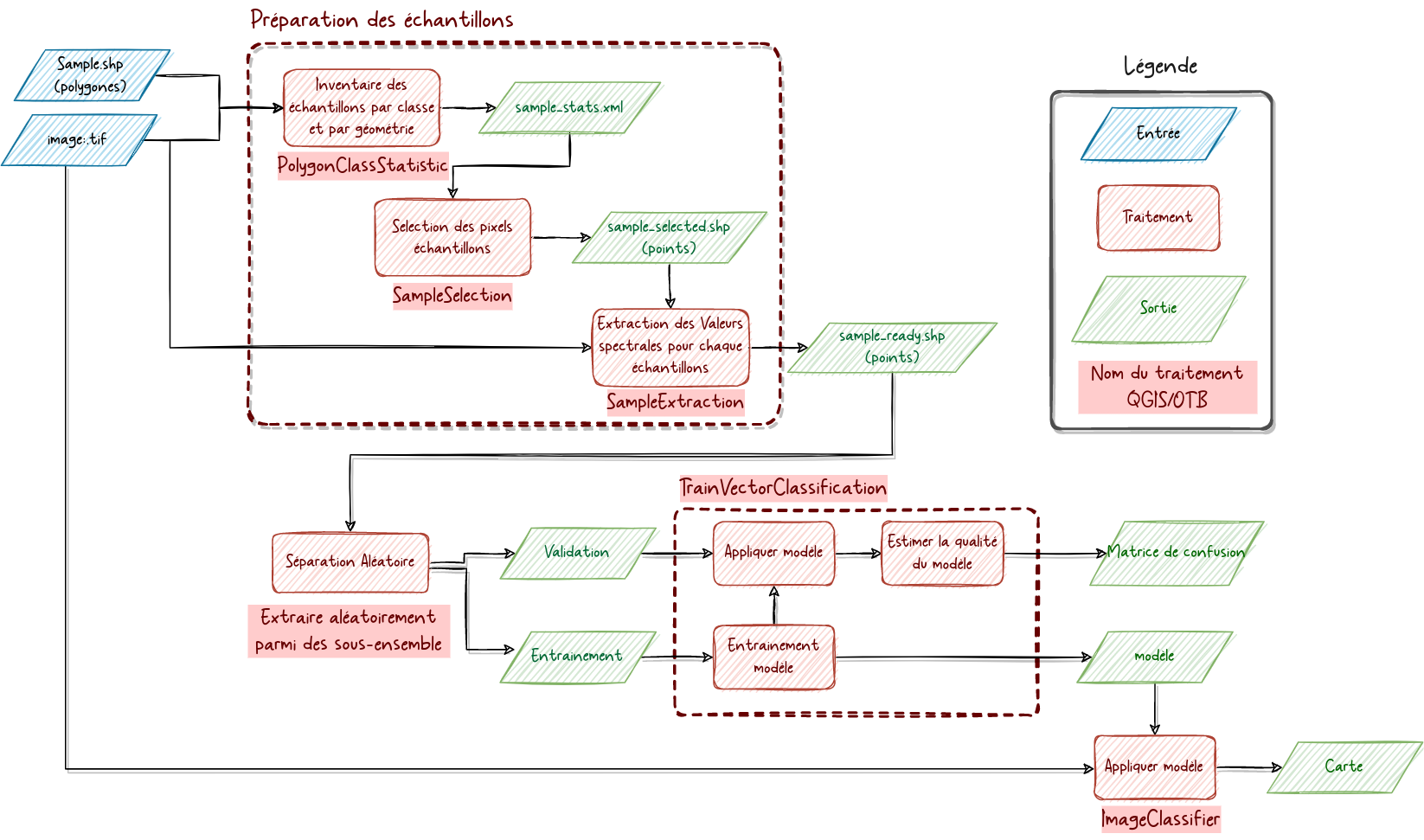
Nous avons déjà évoqué ensemble l'influence la péparation des échantillons, mais d'autres facteurs peuvent inlfuencer le résulats de la classification. L'information contenu dans l'image peut être déterminente (aka sa résolution spatiale, son nombre de bandes et sa date d'acquisition) et la manière dont elle est traitée !
Influence des dates et des primitives
Dans cette partie tu vas cartographier l'occupation du sol selon d'autres niveaux de nomenclature en plus du niveau 1 : le niveau 2 en utilisant le même jeux que précédemment mais pas le même champs de la table attributaire quand il s'agira de renseigner le label numérique des classes; et le niveau 3 en utilisant le jeux d'échantillons tree_species.shp.
Comme tu peux t'en douter, le problème de classification est autrement plus dur que celui abordé pour le niveau de nomenclature 1 : les signatures spectrales de différentes espèces d'arbre sont plus similaires que celles d'occupation du sol aussi variées que de l'eau et du sol nu.
Par ailleurs, tu vas également tester l'influence de la résolution spatiale, spectrale et temporelle sur les résultats de classification pour les différents niveaux de nomenclature. Ainsi, voici les questions auxquelles tu vas essayer de répondre :
1. Diminuer la résolution spatiale de l'image permet-elle d'améliorer les résultats de classification ? L'hypothèse derrière cette question est que la présence de détails plus nombreux permet une meilleure discrimination des objets qu'on cherche à caractériser.
2. Une information spectrale plus riche permet-elle d'améliorer les résultats de classification ? Tu fais l'hypothèse qu'avoir une résolution spectrale plus fine permettra de discriminer différentes essences forestières.
3. Quelle est la meilleure période pour cartographier l'occupation du sol ? Tu fais l'hypothèse que la séparabilité des classes évolue en fonction du temps.
4. a. L'utilisation de plusieurs dates d'acquisitions permet-elle d'augmenter les résultats de classification ? Tu fais l'hypothèse qu'avoir une série temporelle (aka une évolution du comportement spectrale) permettra de discriminer différentes essences forestières par rapport à leur décallage phénologique.
4. c. Utiliser toutes les dates disponibles est-il nécessaire, la sélection de dates clefs ne serait-elle pas pertinente ?
Pour répondre a ces questions, tu disposes des données suivantes :
- d'images Pléaides que tu as utilisées tout au long des séances :
Pleaides_octobre_2013.tifPleaides_décembre_2013.tif
- d'une image pléaides fusionnée :
fabas_octobre_pms_cropped.tif.(cf exercice sur le pansharpenning du TD de prétraitements)
- d'images Sentinel-2 :
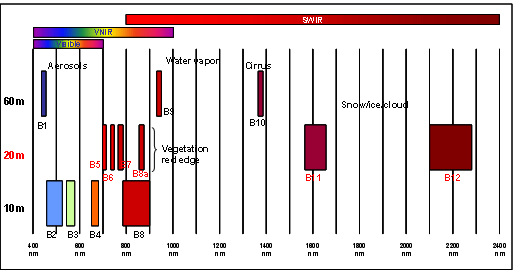
- déjà pré-traitées pour neuf dates (cf tableau ci dessous). Chaque image est composée des bandes 2, 3, 4, 5, 6, 7, 8a, 8 et 11 (voir Figure ci dessous pour pour savoir à quel domaine spectral correspond chaque bande). Les images ont été reprojetés en RGF93 (ESPG:2154), découpé sur le site de la forêt de FABAS et toutes les bandes ont été ré-échantillonnées à 10m.
- sous forme de séries temporelles de NDVI avec différentes sélections de dates (voir le deuxième tableau ci-dessous). Le NDVI a été calculé à partir des bandes 8 et 4.
| Date |
|---|
| 25 Février |
| 17 Mars |
| 06 Avril |
| 16 Mai |
| 05 Juillet |
| 14 Aout |
| 23 Septembre |
| 08 Octobre |
| 17 Novembre |
| Date | Dates |
|---|---|
| all_dates_ndvi.tif | toutes les dates par ordre chronologique |
| four_seasons_ndvi.tif | fev, mai, aout, nov |
| spring_automn_ndvi.tif | mars, avril, oct, nov |
: Quelles comparaisons pour quelles questions ?
Ici tu as donc plusieurs questions et différentes données à ta disposition. La première chose à faire avant de se lancer bille en tête dans des classifications effrénées de toutes les données disponibles, c'est de réfléchir aux comparaisons pertinentes à faire pour répondre aux questions proposées. Quelle comparaison de résultat de classification faire pour répondre à la question 1 ? À la question 2 ? etc.
Ne regarde pas le tableau ci dessous avant d'avoir fait cet exercice, sinon tu ne réfléchiras pas, et c'est mal.
1. Prends d'abord 10 min seul·e pour déterminer quelles comparaisons tu ferais.
2 Prends encore 10 min pour échanger avec tes 2-3 voisin·e·s les plus proches sur les propositions de chacun·e. Plusieurs comparaisons sont possibles pour chaque question.
3 Regarde la tableau ci dessous et compare tes résultats.
Dans le tableau ci dessous figure l'ensemble des comparaisons auxquelles j'ai pensé. Comme tu peux le voir, pour une même question, plusieurs comparaisons sont possibles. Peut être y a-t-il même des comparaisons auxquelles je n'aurais pas pensé. Si c'est le cas je t'invite à m'en parler lors de la prochaine séance, en attendant, on fera comme si j'avais raison 😉.
Par ailleurs, je te propose dans ce tableau des comparaisons pour différents niveaux de nomenclature (cf partie sur les échantillons de références), j'ai éliminé les niveaux de nomenclature qui ne me paraissaient pas intéressants, mais encore une fois, signale le moi lors de la séance prochaine si tu voyais des choses intéressantes à comparer qui ne figureraient pas dans ce tableau.
| Question | Comparaison | Niveau de nomenclature |
|---|---|---|
| Q1 (Res. Spatiale) | Pléiades Octobre MS NDVI VS S2 octobre NDVI | 1 |
| Q1 (Res. Spatiale) | Pléiades Octobre MS VS Pléiades Octobre PMS | 1 et 3 |
| Q2 (Res. Spectrale) | Pléiades Octobre MS VS S2 Octobre | 1 et 3 |
| Q2 (Res. Spectrale) | Pléiades Octobre MS VS Pléiades Octobre NDVI | 1 et 3 |
| Q3 (Dim. Temporelle - 1 date) | Comparaison des deux dates Pléiades MS entre elles | 1 et 2 |
| Q3 (Dim. Temporelle - 1 date) | Comparaison des dates S2 (toutes bandes) entre elles | 3 |
| Q3 et Q2 (Dim. Temporelle et spectrale) | Comparaison de chaque dates S2 (ndvi) avec chaque date S2 (toutes bandes) | 3 |
| Q4a (Dim. Temporelle - toutes dates) | Comparaison meilleure date S2 avec série temp. S2 (NDVI) toutes dates | 3 |
| Q4a et Q2 (Dim. Temporelle et spectrale) | Comparaison série temp. S2 (NDVI) toutes dates avec série temp. S2 (toutes bandes) toutes dates | 3 |
| Q4b (Dim. Temporelle - Selection de dates) | Comparaison des différentes sélections présentées sur le tableau ci dessus | 3 |
| Q4b et Q2 (Dim. Temporelle et spectrale) | Comparaison pour chaque sélection entre séries temp. S2 de NDVI et séries temp. S2 avec toutes les bandes | 3 |
: Comparer différentes sources de données.
Répondre à ces questions va nécessiter la production de nombreuses classifications. Vous allez donc travailler collectivement pour répondre à toutes les questions pour différents niveaux de nomenclature.
L'objectif pour la prochaine fois est de faire une présentation synthétique des résultats permettant de répondre au maximum de questions/comparaisons présentées dans le tableau ci-dessus. Si vous ne pouvez pas tout faire, tant pis. Faites au mieux.
Au-delà des matrices de confusion pour chaque modalité j'attends que vous produisiez des figures de synthèse comme sur les exemples ci dessous :
Plusieurs représentations sont possibles et vous allez devoir faire des choix : est-ce qu'il faut montrer les rappels et précisions de toutes les classes à chaque fois ? À vous de voir ! Choississez les résultats qui vous semblent les plus pertinents.
Quelques remarques cependant :
Organisation
Je vous propose de travailler tous ensemble sur une présentation unique mais vous pouvez par exemple vous répartir par petit groupe pour une traiter une ou plusieurs questions (ou pas, à vous de voir). Mais si c'est trop compliquer de vous organiser à autant, libre à vous de faire des groupes tout à fait séparer et de faire dans ce cas plusieurs présentations.
Si vous ne consituez qu'un seul groupe la présentation peut durer jusque 20 min (pas plus sinon ce n'est plus une synthèse), si deux groupes 10 min max, si quatre groupes 5 min max etc.
Méthode de travail
Pour que vos résultats soit comparables : assurez vous que vous travaillez bien avec les mêmes jeux d'entrainement et de validation ! Sinon comment savoir si les différences que vous observez résultent bien d'une différence de l'image utilisée en entrée et non pas de la séparation aléatoire des échantillons 😎.
Utilisez l'option B de préparations des échantillons pour les nomenclatures de niveau 1 et 2 et A pour la nomenclature de niveau 3.